Database
Files and code
Projective database
- Pairs of piano and corresponding orchestration : LOP_database.zip
- Useful code for processing the midi scores and performing automatic alignment : LOP_database github repository
Symbolic orchestral database
In the case of projective orchestration, this dataset can be used in a pre-training step.Description
This database is a MIDI collection of 196 pairs of piano scores and corresponding orchestrations. The figure of the right-hand side represents the hierarchy of the database and general statistics are given in the table.
The dataset is split between train, validation and test sets of files that represent approximately 80%, 10% and 10% of the full set. The split we used is written in text files with transparent names. For instance, the files from the liszt_classical_archives used for the training step are listed in the liszt_classical_archives_train.txt file.
Warning : The quality of the orchestrations in the ISMLP folder is poorer than the orchestration from the other database. Hence we don't recommand using it from training a orchestration system. We still release them since some files might be useful for other tasks.
| instrument_name | n_track_present | n_note_played |
| tuba bass | 3 | 178 |
| piccolo | 31 | 6717 |
| celesta | 2 | 1108 |
| violin and viola and violoncello and double bass | 14 | 9731 |
| trombone and tuba bass | 1 | 46 |
| english horn | 13 | 6677 |
| trombone | 96 | 25025 |
| violin | 282 | 336580 |
| clarinet | 123 | 159430 |
| trumpet | 111 | 66584 |
| harp | 27 | 21781 |
| double bass and violoncello | 1 | 1275 |
| bassoon | 58 | 109289 |
| timpani | 77 | 31480 |
| tuba | 42 | 6769 |
| percussion | 57 | 8639 |
| violoncello | 135 | 133640 |
| bassoon bass | 73 | 60044 |
| viola | 122 | 111504 |
| piano and violin and violoncello | 1 | 755 |
| piano | 3 | 4485 |
| cornet | 19 | 3739 |
| trombone and tuba | 4 | 2366 |
| oboe | 119 | 140364 |
| flute | 122 | 117829 |
| english horn and oboe | 1 | 762 |
| horn | 190 | 181714 |
| flute and piccolo | 1 | 1575 |
| organ | 3 | 1646 |
| clarinet bass | 4 | 202 |
| double bass | 119 | 94205 |
| saxophone | 1 | 556 |
| voice | 35 | 33597 |
Data representation in LOP
We used a simple piano-roll representation to process the orchestral and piano scores in LOP. A piano-roll \(pr\) is a matrix whose rows represent pitches and columns represent a time frame depending on the time quantization. A pitch \(p\) at time \(t\) played with an intensity \(i\) is represented by \(pr(p,t) = i\), \(0\) being a note off. This definition is extended to an orchestra by simply concatenating the piano-rolls of every instruments along the pitch dimension.

The rhythmic quantization is defined as the number of time frame in the piano-roll per quarter note. It is clear that the rhythmic quantization chosen impact the predictive task we use to train the models. For instance, as the quantization gets finer, an increasing number of successive frames are identical. To alleviate this problem and get rid of the quantization dependency, we remove from the pianoroll repeated event. More precisely, only the time event \(t_{e}\) such that \(\text{Orch}(t_{e}) \neq \text{Orch}(t_{e} - 1)\) are kept in the pianoroll.
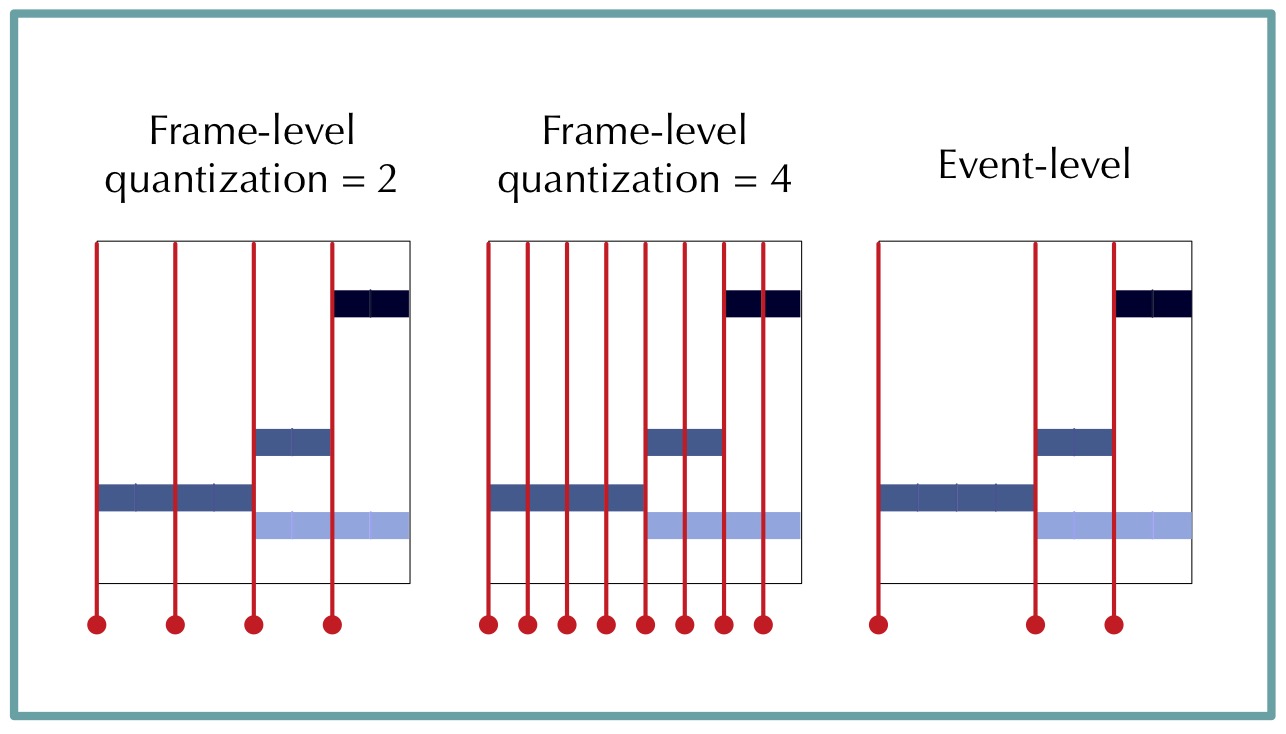
Time alignment
Given the diverse origins of the MIDI files, it is very rare that a piano score and its proposed orchestration are aligned. Indeed, one file can be shorter than the other one, because of temporal dilatation factors or skipped parts.
Those misalignments are very problematic for the projective orchestration task, and in general for any processing which intends to take advantage of the joint information provided between the piano and orchestra scores. Hence, we use the Needleman-Wunsch algorithm to automatically align two scores. To that end, we defined a distance between two chords, which essentially consists in counting the number of jointly activated pitch-classes. This might look too simplistic, be proved to be sufficient.